新唐科技推出基于AI MCU M55M1的離線智能語音控制方案 開啟嵌入式AI新紀元
隨著物聯網和人工智能技術的深度融合,邊緣側智能應用的需求日益迫切。領先的微控制器解決方案供應商新唐科技,正式發布了其基于全新AI微控制器M55M1內核的離線智能語音控制方案。這一創新方案的推出,不僅標志著新唐科技在嵌入式AI領域邁出了堅實的一步,也為智能家居、工業控制、可穿戴設備等眾多領域提供了高性能、高可靠且極具成本效益的本地化智能交互解決方案。
核心技術基石:AI MCU M55M1
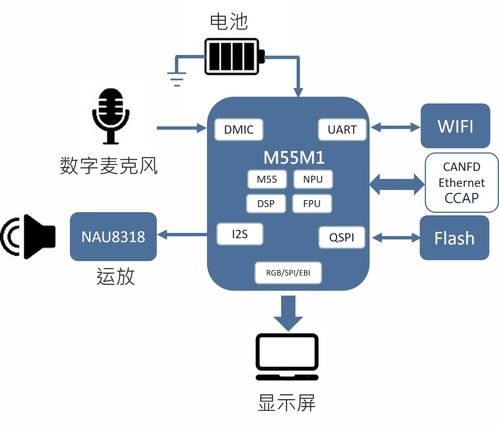
方案的核心在于新唐科技自主研發的AI MCU M55M1。該芯片專為邊緣AI計算而設計,集成了高性能的Arm Cortex-M55 CPU內核,并搭配了Arm的Helium向量處理技術(M-Profile Vector Extension, MVE)。這使得M55M1在保持傳統MCU低功耗、高實時性的具備了強大的數字信號處理(DSP)和機器學習(ML)運算能力。相較于前代產品,其在AI相關算法的執行效率上獲得了數倍的提升,能夠流暢地本地運行語音喚醒、命令詞識別、聲紋識別等復雜的神經網絡模型,而無需依賴云端服務器。
方案核心優勢:真正的“離線”智能
- 隱私與安全:所有語音數據的采集、處理與識別均在設備端完成,數據無需上傳至云端,從根本上杜絕了隱私泄露的風險,滿足了用戶對數據安全日益增長的需求,尤其符合工業及高安全要求場景的規范。
- 實時性與可靠性:離線處理消除了網絡延遲和連接不穩定的影響。無論網絡狀況如何,語音指令都能被即時、準確地響應,確保了控制系統的實時性和可靠性,這對于智能家居中的安防設備、工業現場的緊急指令等場景至關重要。
- 低功耗與低成本:方案經過深度優化,在極低的功耗下即可實現高精度的語音識別。免去了持續的云服務費用和復雜的網絡模塊,有助于終端產品降低整體物料成本(BOM Cost)和長期運營成本。
- 易于開發與集成:新唐科技提供了完整的軟硬件開發套件(SDK),包括優化的神經網絡模型、語音前端處理算法(如降噪、回聲消除)、以及豐富的應用示例。這大大降低了開發者將智能語音功能集成到產品中的技術門檻和開發周期。
應用場景展望
該離線智能語音控制方案具有廣泛的應用前景:
- 智能家居:離線語音控制的空調、風扇、燈具、窗簾等,即使家中斷網,仍可通過語音自如控制。
- 工業物聯網:在嘈雜的工廠環境中,工人可通過特定語音指令安全、快捷地操作設備或查詢信息,提升生產效率與安全性。
- 智能玩具與教育硬件:為兒童產品提供互動式語音交互功能,且無需擔心隱私問題。
- 便攜式醫療設備與健康穿戴:通過語音便捷操作或上報數據,提升用戶體驗。
- 智能車載終端:作為輔助交互手段,在無網絡覆蓋區域仍能實現基礎語音控制。
技術咨詢要點
對于有意評估或采用此方案的企業與開發者,建議關注以下技術咨詢要點:
- 性能指標確認:在特定噪聲環境下的識別率、喚醒率、誤喚醒率;支持的命令詞數量上限及自定義靈活性;典型工作模式下的功耗數據。
- 開發支持評估:SDK的易用性、文檔完整性、以及新唐科技提供的技術支持(如培訓、技術答疑)水平。
- 系統集成考量:M55M1 MCU與其他傳感器、執行器、通信模塊的接口兼容性與驅動支持情況。
- 成本與供應鏈:芯片及方案的整體成本結構,以及新唐科技在產能和長期供貨方面的保障能力。
新唐科技基于AI MCU M55M1的離線智能語音控制方案,精準地抓住了邊緣AI市場對隱私、實時、低功耗和成本敏感的核心痛點。它不僅是一顆強大的芯片,更是一個成熟的、可快速落地的解決方案。隨著萬物互聯向萬物智聯演進,此類本地化智能方案將成為構建可靠、安全、高效智能終端的關鍵基石,有望在廣闊的物聯網市場中開辟出一片新的藍海。對于尋求產品智能化升級的廠商而言,此時深入咨詢并布局該技術,無疑是搶占市場先機的明智之舉。
如若轉載,請注明出處:http://www.0st8ho.cn/product/11.html
更新時間:2026-06-19 02:31:19